Почему растет LOG в MS SQL ?
Друзья, почти ежедневно сталкиваюсь с тем, что на курсе: Администратор 1С, при опросе студентов, на предмет «Как Вы организовали бэкап в MS SQL?». Очень редко кто пишет: «Да, помимо «полного» я делаю и бэкап журналов транзакций».
К сожалению, редко кто делает бэкап ЖТР (
И тем самым открывает прямой путь к таким проблемам как:
«Распух лог в MS SQL», «Сильно увеличился LDF», «Разрастается log, что делать?», «Журнал занял все свободное место на диске», и многое, многое другое.
В этой статье я не буду рассыпать терминами и сложными понятиями гуру специалиста DBA, нет!
Так как вижу реальную картину, реальную проблематику вопроса, на более чем 5000 тыс студентов (Что проходили у нас курс: Администратор 1С). И реальность она несколько в другом!
Большинство не делает бэкапов журналов транзакций, так как не понимает зависимостей (связей), между их созданием и размерами самого журнала (*ldf).
Собственно цель данной статьи, максимально понятно, на простом языке, объяснить и закрыть раз и навсегда проблему растущего лога в MS SQL!

Приступим…
Кратко пройдемся по основам, чтоб даже новички быстро смогли уловить суть и не потеряться в терминах.
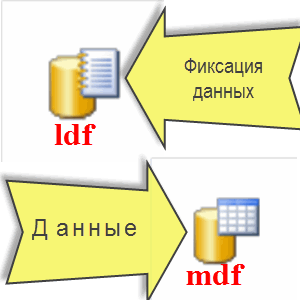
Файл *LDF он же и есть наш журнал транзакций!
Что там хранится?
Каждая база данных SQL Server имеет журнал транзакций, в котором фиксируются все транзакции и производимые ими в базе изменения.
Журнал транзакций — это важная составляющая базы данных. Если система даст сбой, этот журнал поможет вам вернуть базу данных в согласованное состояние.
Если говорить еще проще, благодаря бэкапу ЖТР есть возможность восстановить базу фактически на любой момент времени (вплоть до нужной секунды)!
При этом следует понимать, что никаких по факту данных из 1С в прямом смысле этого слова в журнале нет!
Все данные пишутся в файл *mdf, а вот фиксация этих действий пишется в *ldf, по каждому действию (транзакции), что происходит у Вас в 1С. Все что делают пользователи в 1С, фиксируется в журнале транзакций, только сам факт (фиксация) произошедших событий в базе, а не сами данные.
Собственно отсюда и название «Журнал транзакций». Конечно на практике все сложнее, но в упрощенном для понимания виде все именно так.
Почему растет лог файл в MS SQL (*ldf) ?
Конечно, если учитывать что каждое действие сделанное пользователем в 1С фиксируется в журнале транзакций, то он просто не может не расти! И здесь также стоит отметить, что не только действие пользователя влияет на рост журнала, но и различные регламентные задачи (фоновые различные процессы), особенно сильно заметен рост, когда происходит в базе 1С реструктуризация. Собственно при обновлении конфигурации также можем замечать «взрывной» рост журнала транзакций.
К слову мы только что ответили на частый вопрос: «Вот у меня лог не разрастался» в базе «А», а в базе «Б» растет очень быстро».
Конечно если с базой «Б» пользователи работают интенсивно или различные фоновые, регламентные задачи (их много), безусловно, он будет расти быстрее, такова физика работы «MS SQL»!

MS SQL всегда (в «полной» модели восстановления) будет пытаться зафиксировать, фактически все действия в базе. И журнал будет расти до тех пор, пока мы не сделаем его бэкап, этим мы и «усекаем» его!
«Простая» и «полная» модель восстановления
Да, «полная» модель восстановления подразумевает, что в журнал будем писать «По максимуму» все возможное. Все что сможет записать MS SQL, он туда запишет. Исключения конечно есть. К примеру, когда свободное место закончилось на диске или есть ограничения на сам лог (если установили). Есть и другие причины, но мы сейчас не об этом.
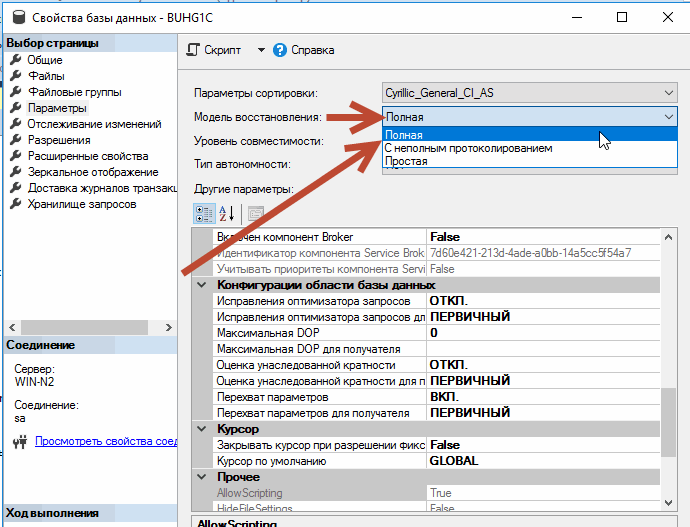
Нам важно понимать одно: «Полная» модель = «Полный» лог! А значит, есть возможность не терять данные, при необходимости восстановится на любой момент времени (фактически до секунды), а выполнив бэкап еще и «заключительного фрагмента журнала» и вообще ничего не потерять!
На сайте Microsoft можно найти информацию о том, что единственная «рабочая» модель, предназначенная для реальной работы, есть только «Полная» модель восстановления! Так как в работе недопустимо терять данные, а это гарантированно произойдет в «Простой» модели восстановления, если случится «сбой».
«Простая» модель восстановления может использоваться для тестирования, разработки, для временного переключения (Обязательно! С предварительным бэкапом базы и лога). К примеру, только на время реструктуризации ее можно включить, а потом обратно вернуть в «Полную» модель. Есть и другие случаи, когда мы только временно переключаем режим с «Полной в Простой» Но работаем всегда в «полной» модели восстановления!
В «простой» модели мы никак не можем восстановиться (в случаи чего) на интересующий нас момент времени. Только на тот момент, когда сделан либо «полный» бэкап, либо «полный» + «разностный»!
Вывод:
Только в «полной» модели мы должны работать! Она не зря «по умолчанию» в MS SQL!
«Активная» и «Неактивная» часть журнала
Сперва дадим ответ на вопрос: «Что происходит в момент создания бэкапа ЖТР ?»
Чтоб разобраться в этом вопросе, нам нужно понимать, что журнал транзакций может быть «условно разделен» на две части: «Активная» и «Неактивная» часть журнала.
«Активная» — содержит изменения, которые были сделаны в базе, но еще не зафиксированы на диске.
«Неактивная» — изменения уже зафиксированы на диске, следовательно, можно усекать неактивную часть журнала (делать бэкап), вплоть до его активной части!
Неактивная часть журнала транзакций содержит информацию о завершенных транзакциях и не используется сервером SQL Server в процессе восстановления данных. Вместо увеличения размера файла журнала транзакций SQL Server будет повторно использовать освободившееся пространство.
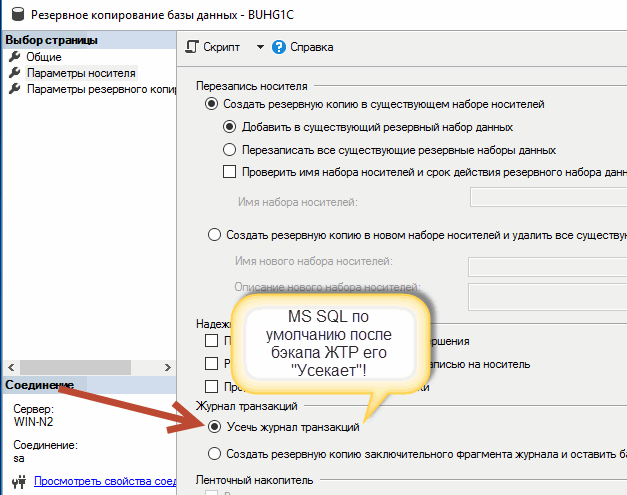
И вот в момент, когда мы создаем бэкап журналов транзакций, мы тем самым «усекаем» его «неактивную» часть (точнее это делает сам MS SQL), вплоть до начала его активной части!
При этом вначале всегда происходит его бэкап, а только после уже «усечение», как на рисунке выше.
Бэкап журналов нужно делать довольно часто (раз на 30-60 мин), особенно если с базой активно работают пользователи, он может вырасти довольно быстро, и конечно без автоматизации этого процесса не обойтись!
Также мы можем сделать и бэкап «заключительного фрагмента журнала транзакций», если нужно восстановить базу на самый последний момент времени. В таком случаи мы также усекаем журнал (ту часть, что есть на момент создания самого заключительного фрагмента журнала).
Вывод:
В «полной» модели восстановления бэкап журналов транзакций НЕОБХОДИМ! Если Вы не хотите в один прекрасный день обнаружить, что свободное место на диске, где он находится, уже закончилось!
Если ЛОГ уже вырос ?
Конечно, если Вы раньше не делали бэкапов журналов, лог соответственно вырос, то здесь одним бэкапом журналов транзакций не обойтись!
И вот почему:
При бэкапе журналов происходит только его «усечение», а при «усечении» высвобождается только пространство внутри файла, а нам нужно еще и его размер на диске освободить. Какой вид у нашего лога после его бэкапа (если он уже вырос) смотрите рис. ниже. Образно говоря «рамки раздвинуты» намного больше самого файла ldf, так как раньше мы не делали бэкап журналов, и поздно выполнив такой бэкап, мы сократили толь
После регистрации откроется полный текст и дополнительные материалы.
Если Вы хотите больше узнать о технической стороне 1С, тогда регистрируйтесь на первый бесплатный модуль курса: Администратор 1С >>>
Успехов Вам, Коллега!
С уважением, Богдан.
Огромное спасибо за эту статью!
Просто всё кратко, по делу и понятно!
Пожалуйста!
Добрый день!
Подскажите, пожалуйста, что делать, если команда не помогла и ошибка репликации при диагностике не ушла?
«Вариант 3. Если получили Replication – значит, что лог не обрезается из-за репликации»